Introduction¶
GeoGig is a Distributed Version Control System (DVCS) specifically designed to handle geospatial data. It draws inspiration from the source code versioning system Git, but employs an approach best-suited to the nature of the data it manages.
Users familiar with Git should find it easy to use GeoGig, though some commands and ideas differ. For users new to version control systems, this document provides a complete description without assuming familiarity.
This user guide does not cover all possible uses of each GeoGig command, but instead introduces the most common operations and workflows. For more information, explore the GeoGig manpages to learn about options not covered here.
Note
GeoGig development is ongoing and still considered unstable, so functionality is subject to change. This documentation reflects the planned functionality that should be available once a stable version is released. While almost everything described here is implemented and functioning, deviations may occur.
GeoGig areas¶
The following is a brief introduction to how GeoGig works and how it handles your data, and also how a GeoGig repository interacts with other repositories. These concepts will be explained in greater detail in the following sections.
GeoGig stores its content in a repository which has three areas: the working tree, the staging area, and the database.
- The working tree is the area of the repository where work is actually done on the data. Data in the working tree is not part of a defined version, but instead can be edited and altered before turning it into a new version that will be safely stored. This means that if you put data on the working tree and then edit it (without copying it to the repository database), the version prior to those edits cannot be recovered.
- The staging area, sometimes also referred as the “index,” is an intermediate area where data is stored before moving it to the database. Data in the staging area is said to be “staged for committing.”
- The database is where the history of the repository is stored, and also, all the versions that have been defined.
Workflow¶
The process of versioning geospatial data consists of the following
- Importing geospatial data into the working tree so it can be managed by GeoGig
- Moving data from the working tree to the staging area
- Committing to database
Note
Steps 2-3 should be familiar to users of Git. Step 1 is an additional step, which is necessary to work with the specific concerns of geospatial data.
The following figure summarizes the above concepts.
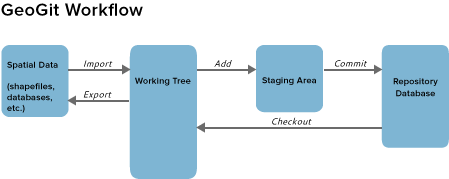
GeoGig workflow
The names in the arrows indicate the corresponding commands for each operation. All commands will be described in the following sections.
Versions¶
As you add new data to the repository database, GeoGig creates new versions that define the history of the repository. While some versioning systems store the differences between consecutive versions, GeoGig stores the full set of objects that comprise each version. For instance, if you have changed a feature by modifying its geometry, GeoGig will store the full definition of that feature, which will be kept in the database along with the previous version of the same feature.
For features not modified from one version to another, the corresponding objects are not stored again and the new version points to the same previous object. So, while each version is a new set of objects, the data for these objects is only stored once.
Collaboration¶
GeoGig is designed to ease collaboration among people working on the same data. Your repository can accept changes from other people working on the same data and you can share, with them, your own changes. Instead of a single repository, there can be an ecosystem of connected repositories, each of them working independently, but communicating and interacting when needed. GeoGig has tools to make this collaboration as easy as possible and to ensure a fluid coordination between a group of collaborators using and editing the same dataset.
The following image shows an extended version of the GeoGig workflow presented before, including the interaction with other GeoGig repositories.
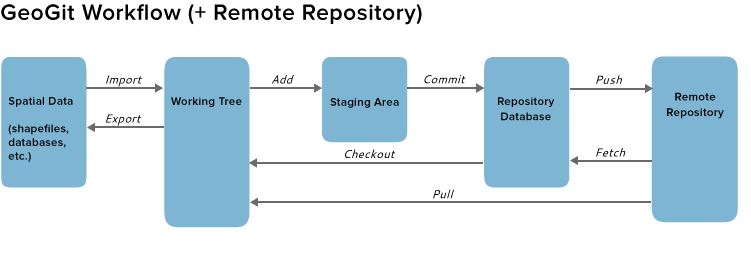
GeoGig works independently of the storage format that you use for your data. It handles only the versioning, ensuring that each revision is stored safely and can be recovered when needed.
![]()